
A nyílt tudomány egyik alapköve az, hogy a kutatási adatok megoszthatóak és újrafelhasználhatóak legyenek. Ez teszi lehetővé, hogy más kutatók ellenőrizzék, megismételjék vagy új szempontból elemezzék az eredményeket. Az olyan pályázati rendszerek mint a Horizon Europe vagy az MTA Lendület ma már elvárják a kutatási adatok nyílt hozzáférhetőségét, és az adatkezelési terv (DMP) is kötelező pályázati elemmé vált.
A helyzet kettős: miközben egyre több adat megosztása válik elvárássá, a kutatóknak etikai és jogi kötelezettségeik is vannak a kutatás alanyaival kapcsolatban. Ez a kettősség komoly kihívást jelent – és pontosan itt merül fel az adatanonimizálás kérdése. Fontos megjegyezni, hogy nem minden adatkészlet osztható meg felelős módon, még gondos anonimizálás után sem. Ilyen esetekben a nyílt hozzáférés helyett a kontrollált hozzáférés a járható út.
Ebben a posztban általános áttekintést adunk az adatanonimizálás alapfogalmairól, a leggyakoribb kockázatokról, valamint bemutatjuk azokat a gyakorlati módszereket és szoftveres eszközöket, amelyek a kutatók adatanonimizálással kapcsolatos mindennapi munkáját segíthetik.
Mit jelent az anonimizálás? – A legfontosabb fogalmak
Mielőtt az anonimizálás módszereire térnénk, érdemes áttekintenünk az alapfogalmakat:
| Fogalom | Magyarázat |
| Anonimizált adat | Visszavonhatatlanul eltávolításra került személyes azonosítók – jogi értelemben már nem személyes adat. |
| Pszeudonimizált (álnevesített) adat | A közvetlen azonosítókat kódokkal helyettesítik, de egy kulcs segítségével az alany újból azonosíthatóvá tehető. Az EU GDPR rendelete értelmében ez még mindig személyes adat! |
| De-identifikált adat | Gyűjtőfogalom: magában foglalja mind az anonimizálást, mind a pszeudonimizálást. |
| Közvetlen azonosító | Az önmagában vett azonosító: név, e-mail, telefonszám, TAJ-szám stb. |
| Közvetett (kvázi) azonosító | Önmagában érdektelen adat, de más adatokkal összefüggésbe állítva a kérdéses személy már azonosíthatóvá válik.: pl. kor, nem, irányítószám, ritka betegség stb. |
A közvetlen azonosítók kezelése viszonylag egyszerű – ezeket töröljük. A közvetett azonosítók viszont a sorok között lapulnak, ezek okozhatják a legtöbb fejtörést.
Miért nem elegendő a közvetlen azonosítók törlése?
Az anonimizálás során a közvetlen azonosítók mellett azokra az adatokra is figyelni kell, amelyek összegzésével a személy azonosíthatóvá válik. Ilyen adat lehet például az életkor, a lakóhely és a foglalkozás együttese. A gondos anonimizálás a kutatási integritás és a résztvevők bizalmának fontos feltétele. A közvetett azonosítók kérdése a következő problémákat veti fel:
Egyedi azonosítás: Ha valaki élesen különbözik a többiektől az adathalmazon belül, név nélkül is felismerhető lehet. Gondoljunk egy kisvárosban végzett kutatásra, ahol egyetlen 95 év feletti résztvevő van – az életkori adatok alapján is kiderülhet, hogy kiről van szó.
Adatkapcsolás: A kutatási adatbázist összevetik más, nyilvánosan elérhető forrásokkal -például közösségimédia-profilokkal vagy egy választói névjegyzékkel. Ahol közös és egyedi egyezés van (pl. életkor + irányítószám), ott az anonimizáció ellenére is lehetséges az azonosítás.
Következtetés érzékeny információkra: Nincs feltétlenül szükség egyéni szintű azonosításra ahhoz, hogy az egyénekről érzékeny információ derüljön ki. Ha egy kisebb csoport tagjai ugyanazt a választ adják egy kényes kérdésre – például az összes férfi munkavállaló egyöntetűen támogatja a szakszervezetet – akkor ez a csoport minden tagjáról érzékeny információt tár fel.
Ahogy az MIT kutatója, Micah Altman is hangsúlyozza az anonimizálás célja, hogy az adathalmaz kutatható maradjon, miközben az abban szereplő egyénekről semmi személyeset ne lehessen megtudni.
Az anonimizálás mint folyamat
Az adatok védelme már a kutatás tervezésénél megkezdődik. Itt azt érdemes végiggondolnunk, hogy milyen adatokra lesz valóban szükségünk. Az adatminimalizálás elve szerint csak azt gyűjtsük be, ami a kutatási kérdés megválaszolásához szükséges. A legbiztonságosabb adat az, ami eleve nem kerül a rendszerbe.
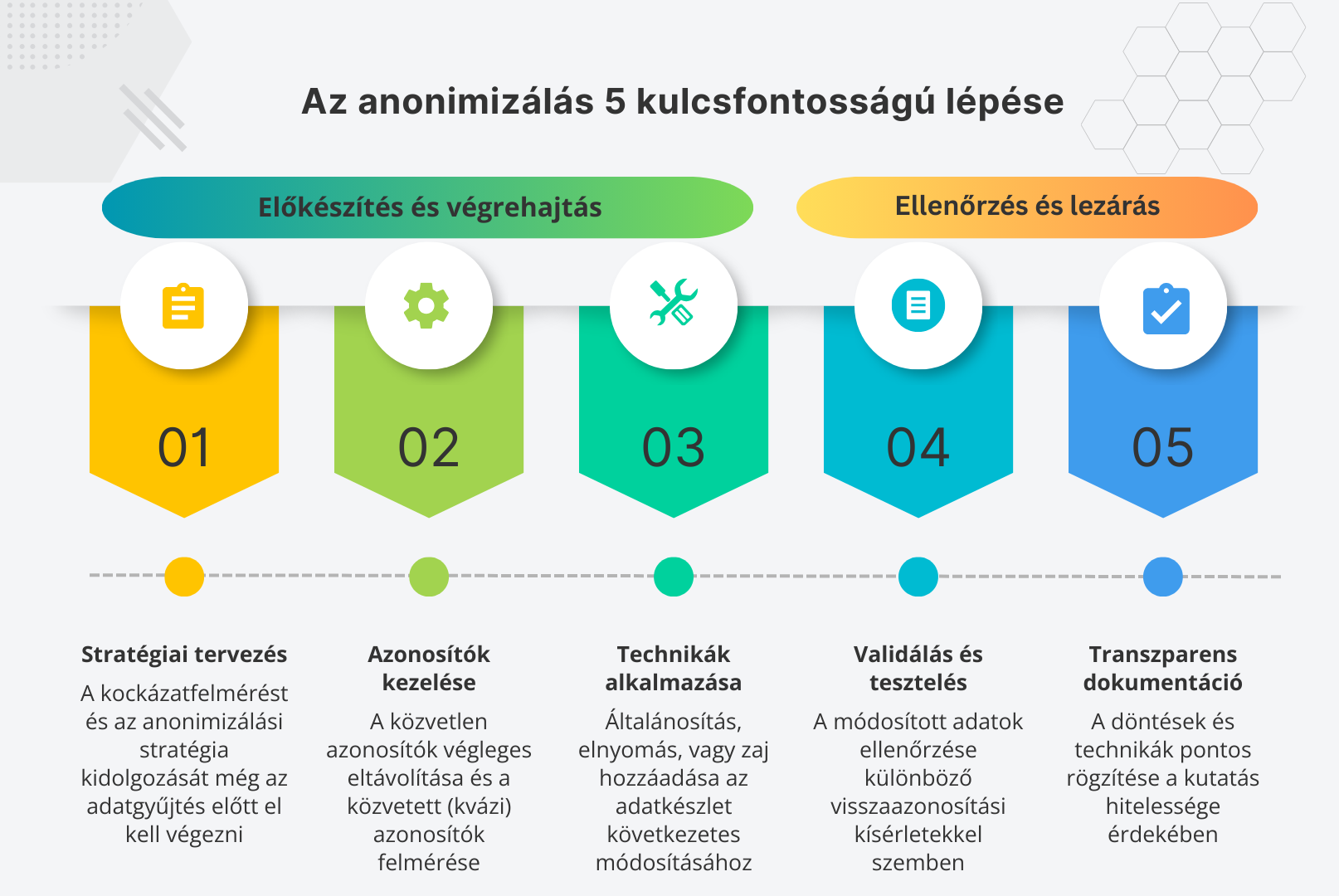
Az anonimizálás folyamata általában öt lépésből áll:
- Tervezés – A kockázatok felmérése és a stratégia kidolgozása még az adatgyűjtés előtt. Ez a kutatási adatkezelési terv (DMP) egyik alapköve.
- Azonosítók kezelése – A közvetlen azonosítók törlése, a közvetett azonosítók kockázatainak felmérése.
- Adatanonimizálási technikák alkalmazása – A választott módszerek következetes végrehajtása (bővebben lent).
- Ellenőrzés és validálás – Teszteljük, mennyire állnak ellen az adatok a visszaazonosítási kísérleteknek.
- Dokumentáció – Rögzítsük a döntéseket és lépéseket. Az átlátható dokumentáció a kutatás tudományos értékének egyik alapja.
Milyen technikák léteznek? – Egy praktikus eszköztár
Az anonimizáláshoz több bevált módszer is rendelkezésre áll. Azt azonban érdemes szem előtt tartanunk, hogy nincs egyetlen, minden helyzetet lefedő megoldás – a megfelelő technikát mindig az adatok jellege és a feltárt kockázatok alapján kell megválasztani.
Egyszerű technikák: csökkentés és általánosítás
- Változók eltávolítása: Ha valamire nincsen szükségünk az elemzéshez (pl. részletes GPS-koordináták), egyszerűen töröljük azt.
- Általánosítás: A pontos adat helyett (pl. „34 éves”) helyett írhatunk „30–39 évest” is. A pontos születési dátum helyett sokszor az évszám is elegendő.
- Lokális elnyomás: Nem az egész adatsort töröljük, és nem is az egész oszlopot alakítjuk át – csak azokat az értéket maszkoljuk, amelyek szembetűnően eltérnek az átlagtól. Az említett 95 éves résztvevő esetében például nem töröljük az életkor oszlopot az egész adatkészletből, hanem ezt az egyetlen értéket cseréljük le egy semleges jelölésre: a 95 helyett * vagy NA kerül be.
K-anonimitás: elbújni a tömegben
A széles körben alkalmazott adatvédelmi modell lényege, hogy úgy alakítjuk át az adatokat, hogy minden rekord a közvetett azonosítók alapján legalább K−1 másik rekorddal azonos csoportot alkosson. Ha K = 5, akkor egyetlen személy adatait legalább 4 hasonló adatsor „veszi körül” – tehát nem tűnik ki a tömegből.
A K értékét a kutató határozza meg a kockázatok alapján – minél magasabb ez a szám, annál erősebb a védelem.
A módszernek van azonban néhány korlátja is. Az egyik ilyen korlát a korábban említett „szakszervezetes” esethez kapcsolódik: ha egy csoport minden tagja ugyanazt a választ adja egy érzékeny kérdésre, a csoporthoz tartozásból következtetni lehet az egyén preferenciáira is – még akkor is, ha senkit sem azonosítottunk névvel.
A másik korlát talán kevésbé nyilvánvaló, de legalább annyira fontos: a k-anonimitás alkalmazása szükségszerűen torzítja az adatokat. Ahhoz, hogy minden rekord beolvadjon egy legalább K elemű csoportba, az adatokat általánosítani kell vagy részben el kell tüntetni – a pontos életkor helyett korcsoport kerül az adatsorba, a konkrét lakhely helyett régió. Ez ugyan védelmet biztosíthat a visszaélések ellen, de ennek ára van, ugyanis az eljárás az adatkészlet részletgazdagságát és pontosságát csökkenti. Minél magasabb a K változó értéke, annál erősebb a védelem – ám így több információ is veszik el. Ezt a kompromisszumot minden esetben tudatosan kell vállalni, és érdemes dokumentálni is – de nem mindegy, hogyan.
A dokumentációban rögzítsük, hogy milyen típusú átalakításokat végeztünk (pl. „az életkort ötéves korcsoportokba vontuk össze”, „a lakóhelyet megyei szintre általánosítottuk”), és mekkora K értéket alkalmaztunk – azt viszont ne rögzítsük, hogy pontosan hány személy volt az egyes csoportokban, és ne soroljuk fel azokat a változókombinációkat sem, amelyek esetleg még mindig egyediek maradhattak. A cél az, hogy a felhasználó értse az adatok korlátait, de a dokumentációból ne lehessen visszakövetkeztetni az eredeti adatokra.
A fenti nehézségek a kutatókat fejlettebb modellek kidolgozására ösztönözték.
Angol nyelvű, közérthető videó a k-anonimitásról:
Differenciális adatvédelem: a haladó szint
Ez az egyik legkorszerűbb megközelítés, amely erős matematikai garanciát nyújt. Az alapelv: egy elemzés eredménye ne változzon érdemben attól, hogy egy adott személy adatai szerepelnek-e az adatkészletben vagy sem. A gyakorlatban ezt úgy érik el, hogy gondosan kalibrált statisztikai zajt adnak az adatokhoz.
Mit jelent ez? Képzeljük el, hogy az életkort vizsgáljuk: ebben az esetben a rendszer minden résztvevő életkor-értékét egy kissé „felfelé vagy lefelé” módosítja. Egyéni szinten ez ugyan elfedi a valós adatot, csoportszinten viszont a pozitív és negatív eltérések kiegyenlítik egymást – az átlag pontos marad, az egyén rejtve.
Angol nyelvű, közérthető videó egyszerű példákkal a differenciális adatvédelemről:
Szoftverek, amelyek megkönnyítik a munkát
A nagy adatkészletek manuális anonimizálása időigényes és sok hibára ad lehetőséget. Léteznek viszont kifejezetten erre a célra fejlesztett, nyílt forráskódú eszközök – amelyek használata egyben a nyílt tudomány elveinek érvényesülését is erősíti.
ARX Data Anonymization Tool – Barátságos grafikus felülettel rendelkező, önállóan futtatható program. Kiválóan támogatja a k-anonimitást és más korszerű adatvédelmi modelleket.
sdcMicro (R csomag) – R-ben dolgozó kutatóknak ideális. Számos anonimizálási technikát és kockázatelemzési módszert kínál, különösen statisztikai adatokhoz.
Amnesia – Rugalmas, könnyen kezelhető eszköz, amely segít a közvetlen azonosítók eltávolításában és a k-anonimitás elérésében.
Érdemes megemlíteni, hogy az utóbbi években mesterséges intelligencián alapuló anonimizáló eszközök is megjelentek – például a Microsoft Presidio vagy különböző felhőalapú szolgáltatások (AWS Comprehend Medical, Google Cloud DLP). Ezek különösen szöveges adatok esetén hasznosak: automatikusan felismerik és elfedik a neveket, helyszíneket, dátumokat és más személyes utalásokat például interjúátiratokban vagy nyílt végű kérdőíves válaszokban is. Egy jól betanított modell percek alatt végez olyasmivel, amit manuálisan órákig tartana elkészíteni. A gyorsaság azonban nem jelenti azt, hogy vakon megbízhatunk ezekben az eszközökben – a kimenetet érdemes saját szemmel is átnéznünk, mert a kontextust a modellek néha félreértelmezik, és előfordulhat, hogy egy-egy azonosító átcsúszik a szűrőn.
Egy fontos megjegyzés: a legtöbb felhasználóbarát „dobozos” szoftver a K-anonimitásra és más, hasonló technikákra épül. A differenciális adatvédelem összetettebb alkalmazásai általában mélyebb technikai tudást igényelnek.
A jogi és etikai oldal – amit nem lehet kihagyni
Az adatanonimizálás nem ér véget azzal, hogy megtaláljuk a megfelelő szoftvert. Európában az EU általános adatvédelmi rendelete (GDPR) az alapvető keretrendszer, amely egyértelműen fogalmaz: az anonimizált adat nem tartozik a rendelet hatálya alá, a pszeudonimizált viszont igen – ez személyes adatnak minősül, így védendő.
De a jogszerűség nem feltétlenül jelenti azt, hogy a helyzet etikai szempontból is problémátlan. Előfordulhat, hogy bár kivitelezhető lenne, tervünk mégis aggályos. A kutatói felelősség arra is kiterjed, hogy megőrizzük a résztvevők bizalmát, ne okozzunk nekik kárt, és nem feledkezhetünk meg arról sem, hogy a számok mögött emberek állnak.
Bizonyos esetekben pedig az a helyes döntés, hogy az adatokat egyáltalán nem tesszük nyilvánosan elérhetővé – még anonimizálás után sem. Ez különösen igaz érzékeny egészségügyi adatokra, kisebbségi közösségekről gyűjtött információkra vagy olyan esetekre, ahol a visszaazonosítás kockázata az ismertetett technikák alkalmazása után is fennáll. Ilyenkor nem a nyílt hozzáférés, hanem a kontrollált hozzáférés a felelős megoldás: az adatok egy megbízható adatrepozitóriumban helyezhetők el, ahol a hozzáférés kérelemhez és jóváhagyáshoz kötött. Ezt nevezhetjük tudatos adatkezelésnek.
Már kutatásunk kezdetén érdemes megtudnunk milyen követelményeket támaszt intézményi etikai bizottságunk, illetve milyen helyi kutatásetikai szabályokat kell betartanunk kutatásaink során.
Gyorsellenőrző lista a mindennapi munkához
Mielőtt nekilátunk az adatgyűjtésnek, érdemes végigmennünk a következő pontokon:
- Kockázatok felmérése – Milyen közvetlen vagy közvetett azonosítók bukkannak fel az adatokban?
- Adatminimalizálás – Ne gyűjtsünk be mindent, amit lehet; csak azt, amire valóban szükségünk van.
- Adatkezelési terv összeállítása – Írjuk le, milyen módon kezeljük az adatokat a gyűjtéstől kezdve egészen a megosztásig.
- Hozzáférés biztosítása – Nyílt megosztás, kontrollált hozzáférés vagy zárolt adattárolás? A döntés az adatok érzékenységén múlik.
- Szoftver-teszt – Nem szükséges azonnal a kutatási adatokon kezdenünk a kísérletezést; egy kisebb tesztkészleten is megtapasztalhatjuk, hogy melyik eszköz illik a feladathoz.
- Nehézség esetén kérjünk segítséget – Az intézményi adatvédelmi felelős, a kutatástámogató könyvtáros vagy az etikai bizottság fontos támpontokat adhat munkánkhoz.
Gondos tervezéssel, a megfelelő technikák alkalmazásával és szakszerű segítséggel az adatanonimizálás terén is megtalálhatjuk a megfelelő egyensúlyt az adatok használhatósága és kutatásban résztvevők védelme között.
Miben tud segíteni a könyvtár?
A PTE Egyetemi Könyvtár és Tudásközpont kutatástámogató csapata segít az adatkezelési terv elkészítésében, az anonimizálási stratégia átgondolásában és a megfelelő eszközök kiválasztásában – akár egy rövid konzultáció keretében is. Ha nem tudja, hol kezdje, vagy egyszerűen hasznos lehet egy külső nézőpont, keressen minket bizalommal:
Hasznos linkek:
Future of Privacy Forum: A Visual Guide to Practical Data De-Identification: https://fpf.org/wp-content/uploads/2017/06/FPF_Visual-Guide-to-Practical-Data-DeID.pdf
Garfinkel, S.L. (2015). De-Identification of Personal Information (NIST IR 8053). National Institute of Standards and Technology. https://doi.org/10.6028/NIST.IR.8053
Research Data Management Support, Huijser, D., Moopen, N., Flores-Dourojeanni, J., Beltrán, M., Bruijn, K. de ., Bruin, J. de ., Capel, D., Dijkstra, F., Einarson, S., Folkers, J., Franzke, A., Graaf, J. de ., Hout, S. van . den ., Huigen, F., Janssen, R. D. T., Jovic, K., Kessels, L., Kleerebezem, S., … Weijdema, F. (2025). Data Privacy Handbook (v2025.05.06) [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.15350653